overleaf template galleryLaTeX templates and examples — Recent
Discover LaTeX templates and examples to help with everything from writing a journal article to using a specific LaTeX package.

This template tracks https://github.com/nsf-open/nsf-proposal-latex-samples which is an unofficial template tested to upload successfully to research.gov.

山中 卓 (大阪大学 大学院理学研究科 物理学専攻)先生が作成された科研費LaTeXを、坂東 慶太 (名古屋学院大学) が了承を得てテンプレート登録しています。 詳細はこちら↓をご確認ください。 http://osksn2.hep.sci.osaka-u.ac.jp/~taku/kakenhiLaTeX/

Master Thesis template to be used in the Master in Cybersecurity (IPVC)

Template for Polish Astronomical Society (PTA) proceedings
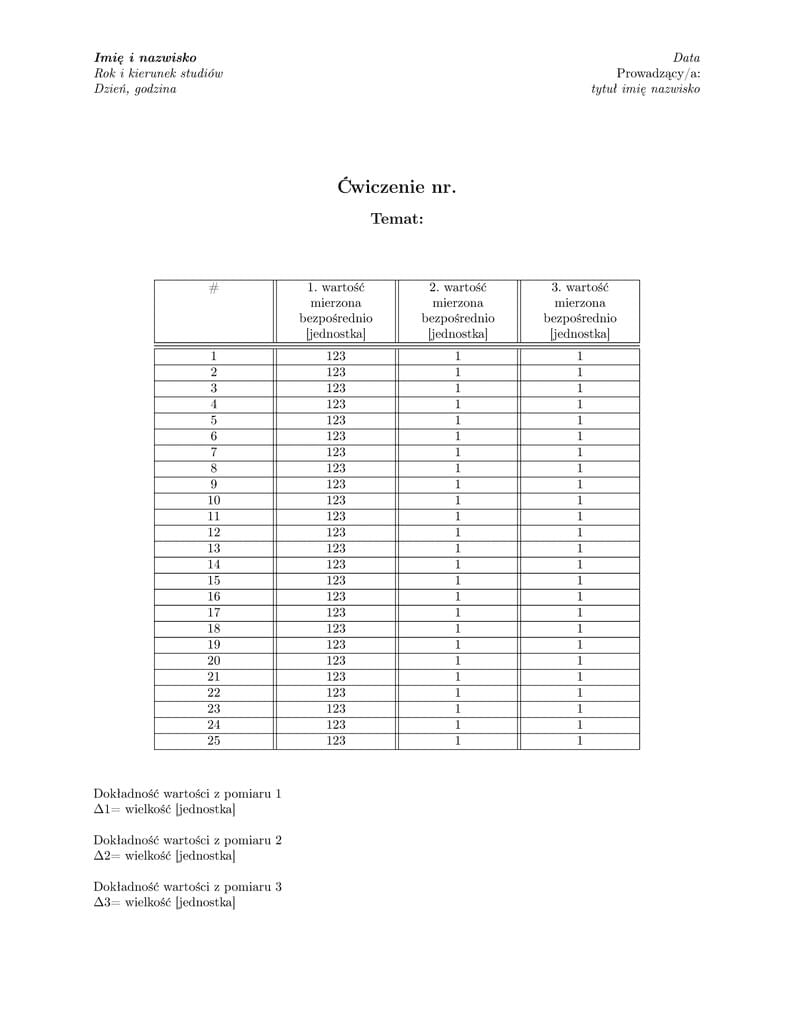
Sprawozdanie Uniwersytet Wrocławski - wzór .pdf I pracowni fizycznej przełożony na .tex

Abstract template for Conference on Recent Advances in Translational Eye Research conference organized by International Centre for Translational Eye Research – icter.pl. More detail on the event - crater.icter.pl

This is the template to be followed by current 3rd-year students of ISE NMIT for preparing the project reports.

This is the project/thesis template for the graduate program. Only the required sections are in this template. The default font size is 11 in Times New Roman, but you can change the font size (10-12 is acceptable) or font if needed.

Unofficial Latex template for the International Conference on Travel Behavior Research (IATBR) 24, based on the suggested word template available in https://iatbr2024.univie.ac.at/abstract-submission/.
\begin
Discover why over 25 million people worldwide trust Overleaf with their work.